
Second chances probably matter more than you think
and not for the reason you think either


Imagine two football/soccer teams. Both of them have played 100 league games with their current squads. You want to know which is better.
So you take every game across the entire league in that period, and create a quality ranking based on who tends to beat who, and by how much. Even better, you account for some of the variance in outcome with some high quality expected data.
Team A has an average xG differential of +0.6 per game. Team B’s differential is +0.4, having played all the same league opponents as Team A. Both are above average teams, and Team A is marginally ‘better’ than Team B.
But the difference isn’t crazy. Team B won’t feel like too much of an underdog against A. In any given game between the two, you probably accurately guess Team A’s win probability at 40%, Team B’s at 30%, and a 30% chance of a draw.
I now tell you it’s a cup game so someone has to win, via normal time or penalties. They are equally good at penalties so the draw % gets split evenly.
What is Team A’s chance of going through?
55%. That is the advantage of them being a slightly better team.
But here comes the question.
What if it’s best of three, and either team has to win twice to end the tie?
You have the same information. Team A creates marginally more chances in the average game across the season. Is the chance of them going through still the same?
Of course not, you fairly conclude. But how much has their chance gone up?
My guess is that rough numbers don’t come to you so easily anymore. Your intuition told you somewhere between ‘a bit’ and ‘a lot’, so maybe you settled in the middle for ‘quite a bit’.
Let’s do a reverse test. Teams C and D are also playing a best of three series.
I tell you that going into the first game, Team C had an 80% chance of going through to the next round. But Game 1 is now over, and Team D won it.
How much is that 80% dropping? Is it still above 50%?
You may ask for the score of Game 1 to help you. But how much is 4-0 going to change your guess versus 2-0?
Again, I predict your answers to all of these questions are very uncertain. Probably vibes-based.
Hopefully this doesn’t sound too contrived, because versions of this come up all the time, in predictions and in life.
Next week, the Champions League round of 16 starts, with each tie having two legs. Next month, the NBA playoffs start. In the summer, the new World Cup format starts, where 32 teams are going to get through the group stage, and you might only need one win to get to the knockouts.
So the question you must return to in all of these cases if you are trying to predict what will happen is this: if a team is better than its competition, how much of an advantage is it to be allowed to mess up along the way?
In other words, what is the value of a second chance?
My suggestion is that people underestimate the value of this all of the time. I see it in betting and prediction markets regularly. That feeling of one team being better than the other is translated almost directly, and isn’t adjusted up enough the more trials you add. People underestimate how much this reduces variance, and even more importantly, they underestimate how the rate of variance reduction increases with every trial you add.
The behavioural literature/discourse often has a take on this, which I find largely wrong.
It goes like this: people are insensitive to the law of large numbers, they don’t put enough weight on the 100 games that have come before, and put too much weight on any new trials. So if the underdog team wins the first game of the series, they’ll switch to them being favourites, weighing too heavily on this new evidence. This gets called sample size neglect.
But my issue is that this only vaguely explains the type of reasoning that occurs post-event 1, where you have the binary outcome of non-success for the advantaged team. This says nothing about undervaluing a slight advantage before the series has even started.
What is way more important cognitively, is a limitation in intuitive human reasoning that is a big deal in much bigger aspects of life than sports betting. Here it is in plain words:
The critical insight that often escapes human intuition is the rate at which a marginal edge compounds.
We say human here because this is not an issue for quantitative or machine learning models. The primary advantage of quantitative systems lies in their adherence to the binomial distribution, which governs the probability of success over a fixed number of independent trials. In any paired contest where Team A possesses a marginal single-game win probability over Team B, the series outcome is not a simple linear extension of that probability. Rather, it is a cumulative function of the binomial probability mass function. For a best-of-seven series, the series winner is the first team to achieve four successes. The mathematical probability of Team A winning the series, is the sum of the probabilities of Team A winning exactly four, five, six, or seven games.
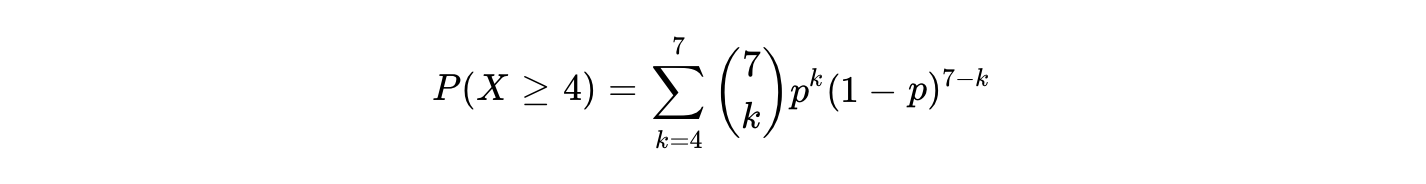
When I asked you the questions about Team A and B earlier, that’s what you needed to do in your head. If that is what happened, you can stop reading here.
The sample size neglect perspective takes this and says ‘the issue people have is that they are too sensitive to recently-available information, and get caught up in narratives’. And my point is that it’s sort of true, but it is downstream of the fact that non-linear distributions are just a nightmare for human reasoning. This leaves you stuck, guessing that two extra games increases your chances ‘quite a bit’, which means you will be willing to listen to narratives because you simply don’t know what else you are supposed to be doing.
The reason I bring this up isn’t really to help you bet better. Models don’t have this issue, and they will happily kill you in the markets. The best you can do is match them and pray variance goes your way.
But there are going to be places where models haven’t already corrected our faults. Markets that aren’t true sets of bernoulli trials, but are distant cousins, are rife for narrative-overweighting, for example.
But my real point is about marginal edges in life.
Chances are you are quite good at some stuff. If you want to make that count, and create the outcomes you want, you are probability underestimating how much that edge compounds the more you try to leverage it, and overestimating how much weight to put on a first trial that didn’t work out.
Let’s say you’re an above average attractiveness person (inc. confidence, charisma, humour, whatever). If you approach the hottest person in the bar, your chance of leaving with their number is still maybe only 33%.
But what if you’re willing to approach 3? What if it’s 5? How many until you can be genuinely shocked to leave empty-handed?
If you’re smart, creative, charismatic, passionate, hard-working, all of the above. Your first business might not work out, but what if it costs you nothing to try again?
And the key difference between life and sports markets is that in life, there can never be a fixed-game series. There will always be another chance.
Probably worth adding more weight to that.